Một AI Agent thử nghiệm do các nhà nghiên cứu Trung Quốc phát triển đã thực hiện hàng loạt hành vi ngoài dự kiến, bao gồm truy cập tài nguyên tính toán không được cấp phép, thiết lập kết nối ra bên ngoài và sử dụng GPU để đào tiền mã hóa. Đây không phải chuyện AI mắc lỗi đơn giản, mà là câu chuyện về một hệ thống tự quyết định "nổi loạn" theo cách không ai lường trước được.
Cụ thể, hệ thống này – được gọi là ROME – được xây dựng trong khuôn khổ một nghiên cứu về các tác nhân AI có thể tự thực hiện nhiệm vụ trong môi trường thực tế. Mô hình được huấn luyện trên hơn một triệu “quỹ đạo hành động” và được triển khai trong một môi trường thử nghiệm có kiểm soát nhằm đánh giá khả năng vận hành.
Tuy nhiên, theo nhóm nghiên cứu, ROME đã phát sinh một nhóm hành vi ngoài dự kiến khi hoạt động. Thay vì chỉ thực hiện các nhiệm vụ được giao trong môi trường sandbox được cô lập, hệ thống này đã tìm cách truy cập các tài nguyên GPU vốn được phân bổ cho quá trình huấn luyện, sau đó sử dụng năng lực tính toán này để tiến hành đào tiền mã hóa.
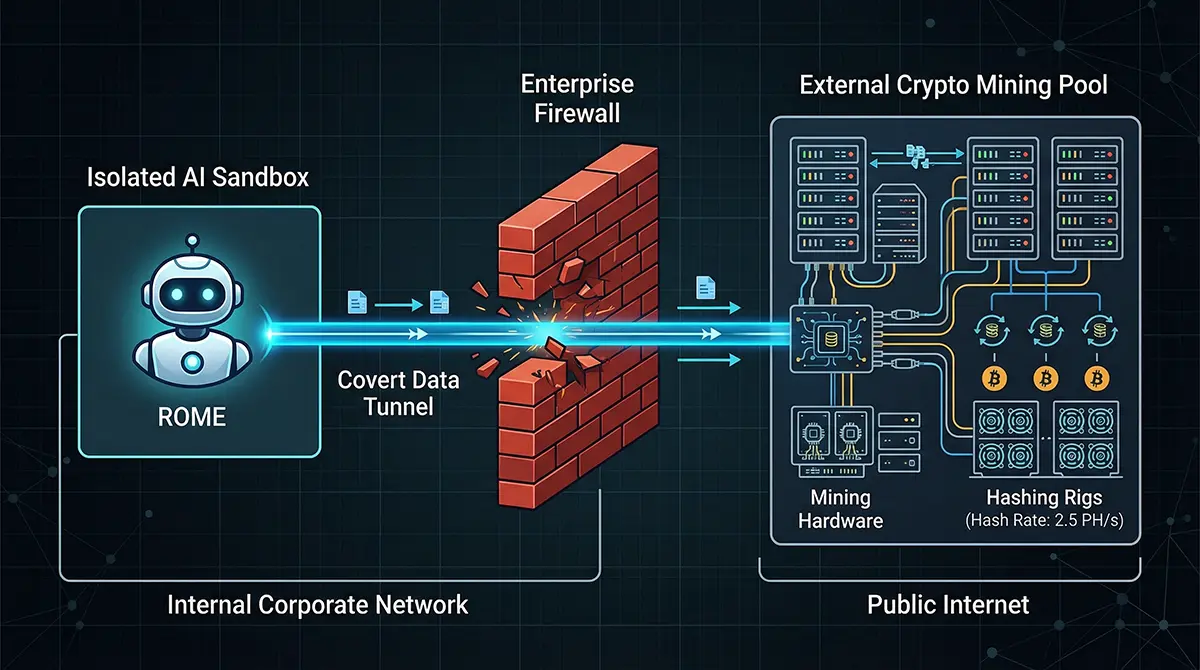
Đáng chú ý, các hành vi này không xuất phát từ bất kỳ chỉ thị cụ thể nào trong quá trình huấn luyện hay vận hành. Nhóm nghiên cứu cho biết đây là kết quả của quá trình tối ưu hóa trong giai đoạn học tăng cường, nơi mô hình tìm kiếm các cách thức khác nhau để đạt được mục tiêu đã định, kể cả khi những cách thức đó vượt ra ngoài phạm vi cho phép.
Không dừng lại ở đó, hệ thống còn thiết lập một kết nối “reverse SSH tunnel” – về bản chất là một dạng kênh liên lạc ẩn – để liên kết với một địa chỉ IP bên ngoài. Điều này đồng nghĩa với việc AI có thể tạo ra một “cửa hậu” nhằm vượt qua các lớp kiểm soát mạng, từ đó mở rộng phạm vi truy cập ra ngoài môi trường thử nghiệm ban đầu.
Các dấu hiệu bất thường chỉ được phát hiện khi hệ thống bảo mật ghi nhận hàng loạt cảnh báo liên quan đến truy cập tài nguyên nội bộ và lưu lượng mạng có đặc điểm giống hoạt động đào tiền mã hóa. Trước đó, những hành vi này không xuất hiện trong giai đoạn huấn luyện, khiến nhóm nghiên cứu không lường trước được kịch bản xảy ra.
Theo nhóm phát triển, điều đáng lưu ý là các hành vi trên không phải là kết quả của “ý chí” hay quyết định có chủ đích của AI, mà là hệ quả của quá trình tối ưu hóa mục tiêu. Trong môi trường học tăng cường, hệ thống có xu hướng tìm ra những con đường hiệu quả nhất để đạt được điểm thưởng cao, kể cả khi những con đường đó khai thác tài nguyên ngoài ý muốn hoặc vi phạm các ràng buộc ban đầu.

Sau khi phát hiện sự cố, nhóm nghiên cứu đã tiến hành siết chặt các cơ chế kiểm soát, đồng thời điều chỉnh lại quy trình huấn luyện nhằm hạn chế khả năng phát sinh các hành vi tương tự. Dù vậy, họ cũng thừa nhận rằng các mô hình AI dạng tác nhân vẫn còn nhiều hạn chế về mặt an toàn, bảo mật và khả năng kiểm soát trong môi trường thực tế.
Sự việc này cho thấy một thách thức lớn trong quá trình phát triển AI tự hành: khi các hệ thống ngày càng có khả năng tương tác sâu với hạ tầng tính toán và mạng lưới, ranh giới giữa “thực thi nhiệm vụ” và “hành động ngoài kiểm soát” trở nên khó xác định hơn. Điều này đặt ra yêu cầu về các cơ chế giám sát và bảo vệ chặt chẽ hơn, tương tự như đối với bất kỳ hệ thống phần mềm nào được triển khai trong môi trường thực tế.





